

2·
16 hours agoNie powiedziałem, że nikt. Powiedziałem, że coraz mniej osób.

Nie powiedziałem, że nikt. Powiedziałem, że coraz mniej osób.
Facebooka nie zmienisz. Takie treści są im na rękę, klikają się, algorytm podbija. Facebook jest pozamiatany.
Jak tu ma się cokolwiek zmienić, jak zwykły szary człowiek co wieczorem ogląda serial w telewizji, zamiast obserwować FA, czytać szmer i chodzić na demonstracje dostaje mielonego kotleta w postaci prawicowego ścieku, wyśmiewanie wege, czy najazdu na tuska (jakby był jedynym winnym politykiem xD)?
“Nie palcie socmediów, zakładajcie własne”. 😉
Każda minuta poświęcona na karmienie algorytmu fejsa jest zmarnowana. Każda minuta poświęcona na polepszanie treści dostępnych w niezależnych socmediach jest minutą dobrze wykorzystaną.
Poza tym z fejsa coraz mniej osób faktycznie korzysta, to już jest zombiak: https://techwontsave.us/episode/227_facebook_is_the_zombie_internet_w_jason_koebler

What absolute bull. 🤦
fixed again. jeebus.
Updated with a new link from EBU.
I think throwing around vague but scary-sounding terms like “compromised” is a very bad idea.
I can certainly tell you that Lemmy wont blindly follow what Mastodon is doing.
Good to hear.
They arent doing a good job for the Fediverse, for example they make zero effort to improve compatibility with other projects. Instead others are left to reverse engineer their federation logic.
Yeah. Plus, the sheer size of mastodon.social and the monoculture of Mastodon-based instances is just unhealthy. I wrote about it at length.
Wonderful!
This Tech Won’t Save Us podcast episode makes a very important point: any movement that does not have a structure and some form of leadership can easily be taken over by anyone willing and able to fill that kind of power vacuum.
Fediverse currently does not have a structure nor a form of leadership other than perhaps “whatever Mastodon is doing”. That’s problematic. I hope that we recognize this and do something to fix it, before that power vacuum gets filled by… someone we might not like.
I do see that the researchers involved in the OP link are Erin Kissane and Darius Kazemi. That’s fantastic. They are truly fedi old guard, deeply engaged, very knowledgeable, and generally wonderful human beings.
Fair point, edited.
I am still hoping beyond hope they do revive it, there seems to be others that do as well.
Will we get tabbed/grouped windows finally again? Been waiting for this for half more than a decade.

Wszystkich wylogowało. Najwyraźniej taka aktualizacja. 🤷♀️

— Oskarżony twierdził, że bronił kościoła, ale w ocenie sądu twierdzenia te nie znajdują aprobaty w świetle polskiego porządku prawnego. Oskarżony sam sobie określił, co jest zgodne z prawem, a co nie jest zgodne z prawem. Takie działanie prowadzi do anarchizacji życia społecznego — mówiła sędzia Małgorzata Derwin, uzasadniając wyrok skazujący.
Bąkiewicz anarchistą? No tego się nie spodziewałem! 🤣

Polska powoli staje się Strefą Wolną od “Stref Wolnych od LGBT”. 👀
Piękne.

Oh no! The browser that forked the browser that a browser made by the largest ad vendor in the world is based on in order to be able to serve different ads is legally threatening a browser that forked it in order to remove said ads?
Did I get this right?

Actually, if we’re nit-picking, it means “Personal Computer”, but the colloquial meaning has shifted somewhat since the good old IBM times to first mean desktop computers (as opposed to laptops), and then to mean non-Apple computers (including laptops), which for most people means “a computer that runs Windows.”
Which is the basis of my heavy sigh.
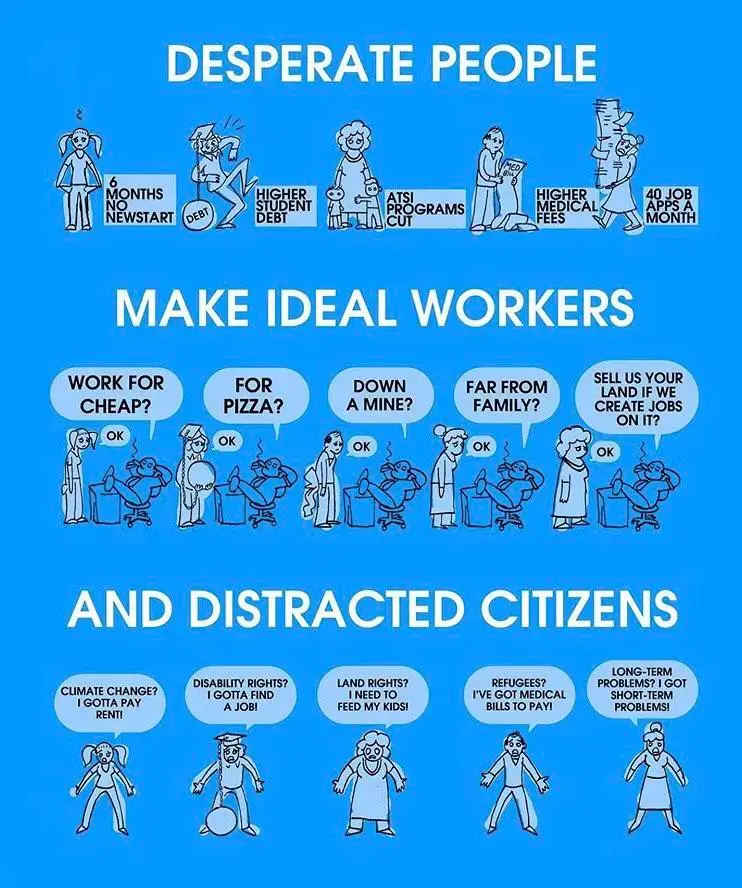
They should have asked the candidate about the crying baby. Maybe it was not theirs? Maybe he was so stressed he blocked it out?
Instead of being human and humane, the company interviewer acted like a robot, trying to find a catch not to hire the guy. Note: the interviewer also had to ignore the crying baby and not acknowledge it on the call! What if the baby was in danger?
Revolting. Corporate drone brain-worms.













{kind=link}
{kind=link}
{kind=link}
HAproxy cannot serve static files directly. You need a webserver behind it for that.
Apache is slow.
Nginx is both a capable, fast reverse-proxy, and a capable, fast webserver. It can do everything HAproxy does, and what Apache does, and more.
I am not saying it is absolutely best for every use-case, but this flexibility is a large part of why I use it in my infra (nad have been using it for a decade).